
Image Classification Based on Few-Shot Learning
Published:
This blog classifies and summarizes the current image classification algorithms based on Few-shot learning. According to the modeling methods of different data types, Few-shot image classification algorithms are divided into convolution neural network model and graph neural network model. Convolution neural network model is divided into four learning paradigms: transfer learning, meta learning, Bayesian learning and dual learning. Two kinds of algorithms are introduced in detail. Finally, for the current Few-shot image classification algorithm, we discuss the ethical oriented implications in terms of interpretability and privacy.
Introduction
Background
Image classification is a hot research topic. Typical image classification algorithms involve two problems, one is how to better represent image features, and the other is how to learn good model parameters. With the development of deeper design of convolutional neural networks (CNN), the representation ability of image features becomes stronger and stronger. Before CNN was born, researchers extracted image features through artificially designed image features, such as Scale-invariant feature transform(SIFT) [1], Histogram of oriented gradient (HOG) [2], Bag-of-words (BoW) [3], etc, However, they are usually hard to design and not general. CNN based deep learning model has achieved great success in 2012 ILSVRC challenge. At the same time, with the development of computing hardware and optimizing algorithm, deep learning has achieved excellent performance in image classification [4].
Driven by data, the model can learn effectively. However, a small dataset will lead to over fitting problems. Simple data augmentation (DA) and regularization can alleviate the problem, but it has not been completely solved [5]. In 2003, Li et al. proposed One-shot learning problem for the first time and used Bayesian framework [6] to learn visual objects. Compared with it, deep learning algorithms can achieves better in the small sample image classification. There are two factors for the emergence of Few-shot learning, One is the small amount of training data. For example, in the medical field, medical images are generated from cases, but a small number of cases can not support a deep algorithm. The other is to make the machine learn to learn in the human way. Human can learn to classify and recognize samples given a small number of examples, and has the ability to quickly understand new concepts and generalize them [6]. Few-shot learning has been applied in many image processing tasks, such as object recognition, semantic segmentation, image retrieval. Researches [7][8] discuss and analyze Few-shot learning from different perspectives, such as the number of samples, the number of labeled samples, the prior knowledge, etc.
From 2010 to 2015, a large number of researches used semantic transfer to solve the problem of insufficient training samples. For example, Mensink et al. [9] used clustering and metric learning methods to classify ImageNet datasets, and explored KNN (k-nearest neighbor) and NCM (Nearest class mean) classifiers to learn a metric through the semantic feature of each class. It can be shared between training and testing categories to achieve the transfer; In [10], semantic knowledge transfer is extended to transductive inference, which uses known categories to infer the representation of unknown categories, calculates the sample similarity of unknown categories, projects the data into a low dimensional semantic space when constructing the spatial distribution of data, and further finds the spatial distribution of the data. Good classification results are obtained on AwA (Animals with attributes) [11], ImageNet and MPII composites activities; In [12], a transductive multi-view embedding framework was proposed to solve the problem of domain shift, and heterogeneous multi-view label propagation was used to solve the problem of sparsity. The complementary information provided by different semantic representations was effectively used, and good results were achieved on the datasets of AwA, CUB (Caltech-UCSD-Birds) [13] and USAA (Unstructured social activity attribute) [14]; In order to solve the problem of attribute learning of social media data with sparse and incomplete labels, Fu et al. \cite{fu2013learning} proposed a model of learning semi latent attribute space by using the idea of zero sample learning, which can express user-defined and potential attribute information, and achieved good results on USAA datasets. These papers mainly focus on Zero-shot learning. However, this blog aims to introduce the image classification algorithms based on small samples, so it is more focused on the Few-shot learning.
In recent years, the existing image classification algorithms based on few-shot learning are mainly based on deep learning. Several methods are used, such as data augmentation to increase the number of samples, extracting image features through attention mechanism and memory mechanism, and designing the mapping relationship between feature network and classifier. Transfer learning, meta learning, dual learning, Bayesian learning and graph neural network (GNN) are also used in the task of Few-shot image classification. The Few-shot learning algorithm described in this blog is designed for image classification task. The algorithms in [7][8] are applied to not only image classification, but also image tasks such as recognition and segmentation, as well as voice and video tasks. Firstly, this blog focuses on the Few-shot image classification algorithms and summarizes them. Secondly, this blog explores different methods, and divides them into CNN model and GNN model.
Problem definition
Few-shot learning refers to the learning tasks when there are few training samples in each class. Generally, we also hope that the algorithm can quickly learn on new classes by learning a large number of base classes with only a small number of samples. Specially, if there is only one training sample in each category, it is called One-shot learning. Few-shot learning includes One-shot learning.

The process of Few-shot image classification is shown in Fig. 1, which includes three steps: preparing dataset, constructing model for image feature extraction and designing classifier. The following is a detailed introduction of the three steps of establishing Few-shot image classification process.
Dataset processing
In this blog, we introduce two ways to process Few-shot image data set. One is data augmentation including number augmentation and pattern augmentation. Number augmentation refers to the expansion of samples, while pattern augmentation refers to making different samples contain more semantic features. The second is not to process the dataset. In the case of a small number of samples, make the model adapt to the data. For Few-shot datasets, it is very important to design a network architecture for extracting features with strong representation ability.
The number of samples in Few-shot image dataset is not enough for the model to capture stable data patterns, and the convolutional neural network often needs a large number of labeled training samples, so the most direct solution is data augmentation. Data augmentation includes three ways: The first method is through rotation, noise addition, clipping, compression, and so on. The second is using generative models to obtain new samples. For example, Jia et al. proposed using Bayesian method to generate new samples [15]. GAN (Generative Adversarial Networks) can provide more generated images for training samples and increase the diversity. In 2017, Mehrotra et al. proposed the network structure combining GAN and siamese network. The third is using function transformation. For example, Dixit et al. use corpus with attribute annotation to generate new samples [16]. If the collected data contains a small number of labeled samples and a large number of unlabeled samples, the labeled samples can be used to label unlabeled samples, and the generated pseudo samples can also be used as additional training samples.
Feature extraction
Feature extraction is to establish a model to adapt to the data distribution, which can extract the effective features of the image. For a model, the extracted features should effectively represent the image and achieve better classification performance. Several novel ideas have been applied, such as attention mechanism and memory mechanism.
1) Attention mechanism
Attention mechanism is the unique brain signal processing mechanism of human vision. Human vision can scan the global image quickly to obtain the important area, and then suppress other useless information, which greatly improves the efficiency and accuracy of visual information processing. Attention mechanism is widely used in the deep image processing. It always pays attention to some regions of interest. Therefore, in the process of establishing image feature extraction model, attention mechanism plays the role of further extracting image information into effective information and learning different parts.
Attention mechanism in mathematical form can be understood as weighted summation, usually using SoftMax function, and improving the fitting ability of the model because of additional parameters. Research [17] uses a single attention mechanism in the image feature extraction, but research [18] argues that the single one was not effective enough. In order to reduce the gap between visual information and semantic information, multi attention mechanism is proposed to link category label information and visual information.
2) Memory mechanism
Recurrent neural network (RNN) solves the problem of short-term memory, and its variant Long short-term memory (LSTM) solves the problem of short-term memory and long-term dependence. The memory mechanism based Few-shot image classification algorithm can be divided into two categories: 1) Directly use LSTM to encode images to improve the representation ability of image features; 2) Use the read-write controller to write and read the memory information.
Classifier
The design of a classifier depends on the effectiveness of image features and the adaptability between the classifier and image features. The latter means that the classifier can distinguish different types of image features to the greatest extent under the assumption that the image features are effective. In Few-shot learning, most algorithms build a fully connection layer with SoftMax at the last layer of convolutional neural network, or apply K-nearest neighbor (KNN) algorithm to the extracted image features, or regenerate the weight of the classifier so that the model can be applied to both the base class dataset and the new class data set. At present, the existing meta learning methods generally do not study the problem of classifying the base class and the new class together.
Classifier is essentially to measure the similarity of features and distinguish different categories. KNN, the simplest measurement method in traditional machine learning, can measure the distance between each sample, and then sort the similarity distance. For example, 1-nearest neighbor (1-NN) can be used to complete One-shot learning task, but experiments show that the performance is not good [19]. In addition, support vector machine (SVM) can also be used for classification. Neighborhood component analysis (NCA) [20] and its nonlinear method [21] are also the feature measurement methods. Also, cosine distance, Euclidean distance and dot multiplication are used to measure feature distance in Few-shot image classification.
Generally, when a model learns a new category, it will forget the previously learned category. Different from the previous work, Gidaris et al. [22] proposed a classifier weight generator based on attention mechanism. Similarly, Chen et al. replaced linear classifier with distance based classifier to compare them on different datasets.
Dataset and evaluation metrics
Public dataset
In recent years, the Few-shot image classification datasets mainly include Omniglot, CIFAR-100, Mini-ImageNet, Tiered-ImageNet and CUB-200. Tiered-ImageNet has a large number of samples and categories, and there are plenty of samples in each category. Also, there are a small number of categories in Mini-ImageNet, CIFAR-100 and CUB-200, but they have many samples in each category. On the contrary, Omniglot has many categories and few data samples. The images in Omniglot datasets are characters, which contain simple types and patterns, and the classification accuracy based on it is often higher. What in other datasets are natural images, which contain complex image patterns, and the classification accuracy is often relatively low.
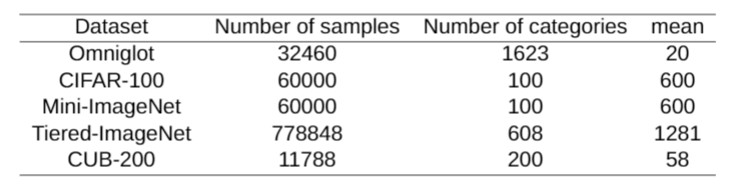

The details of the datasets are shown in Table. 1 and Fig. 2. All the public datasets used in Few-shot image classification have more than 100 categories, and more than 10000 samples. Tiered-ImageNet dataset has even more than 770000 data samples. The average number of samples in each class of Omniglot data set and CUB-200 dataset is less than 100, and that of Tiered-ImageNet dataset is more than 1000.
Evaluation Metrics
The evaluation metric of Few-shot image classification algorithm is usually called N-way K-shot [5]. Top-1 and top-5 are also used to evaluate the accuracy of image classification [23]. N-way K-shot: select n types of image samples, and select k samples or sample pairs for each type. Generally, $n \in {5, 10, 15, 20}$, $K \in {1, 5}$. In the model training stage, a model based on n × K samples or sample pairs are trained. In the validation and test phase, K samples or sample pairs from n classes are selected to perform N-way K-shot classification task. Top-1 refers to the accuracy that the first category of prediction is consistent with the actual results. Top-5 refers to the accuracy that the top five categories of prediction include the actual results.
Few-shot image classification algorithms
For different types of data modeling, this blog divides the Few-shot image classification algorithms into convolution neural network (CNN) model and graph neural network (GNN) model. According to the learning paradigm, CNN model can be divided into transfer learning, meta learning, dual learning and Bayesian learning. Few-shot image classification based on transfer learning can be realized in three ways: feature-based, correlation based and shared parameter based. There are three ways to realize the Few-shot image classification based on meta learning: measure based, optimization based and model based. There are two ways to realize the image classification based on dual learning, one is to use Auto-Encoder, the other is to use Generative Adversarial Networks (GAN). In this section, we will introduce different algorithms in terms of transfer learning and meta learning.
Transfer learning
Using transfer learning [24][25] can reduce the cost of model training and make convolutional neural network adapt to small sample data. The idea of transfer learning is that learning between similar tasks has the same rules, and learning the $n^{th}$ task is simpler than the first task. Transfer learning focuses on the target task. Given a source domain $D_S$, a learning task $T_S$, a target domain $D_T$ and a learning task $T_T$, the purpose of transfer learning is to use the knowledge on $D_S$ and $T_S$ to help improve the learning of the prediction function $f_t(x)$ on the target domain $D_T$, so as to better perform the learning task $T_T$, Where $D_S \neq D_T$ and $T_S \neq T_T$. If the source data and target data in transfer learning are different but have correlation [26], further processing is needed.
![]()
As shown in Fig. 3, transfer learning is realized in the stage of image feature extraction. Specific transfer learning methods can be divided into feature-based, correlation based and shared parameter based. If the base class is regarded as the source domain data and the new class as the target domain data, taking the knowledge transfer from the base class data to the new class data as an example, the feature-based transfer is to find out the common features between the base class data and the new class data, and transfer the knowledge of the base class data through the feature transformation for the new class data classification. The difficulties of this method are: 1) how to find the common features of the base class data and the new class data; 2) how to transfer the features. Correlation based transfer is to establish the mapping of knowledge between base class data and new class data. The difficulties of this method are: 1) how to define the mapping; 2) how to build the mapping. The shared parameter based transfer needs to find the shared parameters or the same prior distribution between the base class data model and the new class data model, and use them for knowledge transfer. The difficulties of this method are: 1) how to find shared parameters; 2) how to find prior distribution. When looking for the common features, knowledge mapping relationship, shared parameters and prior distribution of source domain data and target domain data, it is important to build a network structure that can effectively extract image features and a suitable way of knowledge transfer, Moreover, we should ensure that the model has good classification performance in both source domain data and target domain data.
Feature based Transfer learning
Hariharan et al. [27] used the pattern between the base class samples to transform the new class samples, so as to increase the number of training samples.Specifically, two samples are extracted from Class A, and there is a certain transformation pattern between the two samples. Then a sample is taken from class B, and the same transformation pattern is implemented between the two samples in class A to generate new samples. This method uses ImageNet1k dataset, which is divided into base class dataset and new class dataset. The base class contains a large number of training samples, and the new class contains a small number of training samples. The training model is divided into two stages: 1) the representation learning stage extracts the features from the augmented base class data and constructs the classifier, 2) in the small sample learning stage, the model is trained based on the base class data and the new class data to obtain the common features of them, and the features extracted in the first stage are used to classify the base class and the new class. In order to make the classifier adapt to the base class data and the new class data at the same time, a new loss function is proposed to reduce the loss:
\begin{equation} \operatorname{Loss}=\min {W, \phi} L{D}(\phi, W)+\lambda L_{D}^{S G M}(\phi, W) \end{equation}
where $L_{D}$ denotes the loss on the base class data, and $L_{D}^{S G M}(\phi, W)$ denotes the loss caused by the difference between the base class and the new class, which is a SGM (Squared gradient magnitude). Choi et al. [28] proposed SSMN (Structured set matching networks) for small sample learning of sketch image and natural image, which uses the correlation between samples. The model has good performance in three self-built datasets: multi-label sketch image dataset, natural image dataset and mixed dataset. It uses the multi-label information for intra domain or cross domain transfer. CNN and bidirectional LSTM are used to extract the local features of the base class samples and the new class samples and map them into the same space to calculate the local and global similarity to achieve image classification.
Correlation based Transfer learning
Compressing knowledge into a single model has been proved feasible by Buciluaana et al. Furthermore, in 2014, Hinton et al. Proposed the concept of knowledge distillation for the first time [29]. By introducing relatively complex teacher networks, they can induce the training of simplified and low complexity student networks and transfer knowledge from teacher network to compressed student network to realize knowledge transfer. The student network can be obtained by pruning the teacher network or compressing, or redesigning a new network architecture. The purpose of knowledge distillation is to reduce the network architecture and retain the knowledge of the network. In order to achieve this goal, a new temperature parameter Tem is proposed to soften the output probability:
\begin{equation} q=\frac{\exp \left(\frac{z_{i}}{T e m}\right)}{\sum_{i} \exp \left(\frac{x_{i}}{T e m}\right)} \end{equation}
where $Z_i$ is the output of the previous SoftMax layer, and Q is the softened probability output. After dividing the prediction output of the teacher network by Tem, SoftMax transformation can be performed to obtain the softened probability distribution. The values range from 0 to 1, and the distribution of values is relatively mild, that is, one or more large or small probability is given for the category of the sample. The larger the value of Tem is, the milder the distribution is. When the value of Tem decreases, it will lead to enlarge the probability of error classification and introduce unnecessary noise.
Shared Parameter based Transfer learning
Oquab et al. [30] adopted fine-tuning strategy. In this algorithm, the image was decomposed into multiple blocks to realize data augmentation, which enhanced the ability of the model to recognize the image from a local perspective. Oquab et al. believed that the middle-level features extracted by convolutional neural network could well represent the image. Using the model pretrained on ImageNet dataset, the middle-level features of the image were extracted, and the classification layer was reconstructed to build a new network to do classification.
Qi et al. [31] proposed a combination of transfer learning and incremental learning. The algorithm uses convolutional neural network as feature extractor to share parameters. After feature extraction of new samples, a classification weight vector is generated, which is extended into the pretrained classifier weight to adapt to the classification task of new samples.
Meta learning
Meta learning, also called learning to learn, is an important research topic in the field of machine learning. The traditional research mode of machine learning is to acquire data sets of specific tasks, and then use these data sets to train the model from scratch. However, human beings can learn the same type of task or common task quickly by acquiring past experience, because they know how to learn.
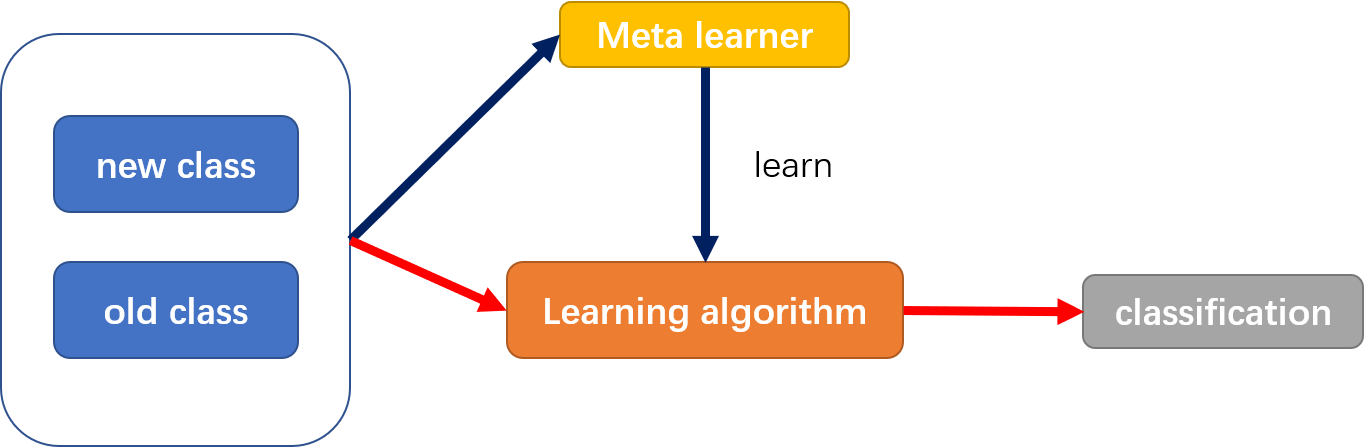
As shown in Fig. 4, if feature extraction is regarded as the process of machine learning on the dataset, then the meta learner is to evaluate the learning process, that is, to obtain learning experience through learning, and then use these experience to evaluate the final target task. A common meta learning method is to encode learning algorithms into convolutional neural networks, including distance metric based meta learning and model-based meta learning. Another way is optimization based meta learning, which aims to make the network have a good initialization.
Metric based meta learning
Based on fixed distance metric, In 2015, Koch et al. [19] proposed a deep convolution siamese network for character recognition, which uses global affine transformation to increase the training data set. In this algorithm, a siamese network is trained to measure the similarity of samples, that is to say, the samples pass through the same network structure. The Euclidean distance is used to measure the similarity of the features learned from the samples, and the test samples are classified according to the learned feature mapping. Although the proposed method does not rely on prior knowledge and is easy to simplify the model, it lacks the auxiliary information of prior knowledge, so it is difficult to achieve good results in small sample image classification tasks on more complex datasets.
Based on unfixed distance metric, Choi et al. [28] proposed structured set matching networks (SSMN) for the classification of sketch images and natural images. In this model, RNN is used to calculate the local similarity of local information corresponding to all labels between images, and the local features and global features are combined to enhance the interpretability of images by using multi label data, but it also increases the workload of data annotation. When human beings distinguish things, they are used to comparing different things. According to this simple idea, the end-to-end Relation network (RN) proposed by sun et al. [32] in 2018, which learns a deep distance to measure different samples of meta learning tasks. The Relation network consists of two modules, the embedded module and the correlation module, The embedded module extracts the features of different samples, and the correlation module catenates the features of different samples to get the correlation measurement score between different samples.
Model based meta learning
In general, meta learning is divided into two stages: slow learning of meta level model on different tasks and fast learning of benchmark model on a single task. The purpose of meta level model is to learn common knowledge in different tasks, and then transfer it to benchmark model to help learning on a single task.
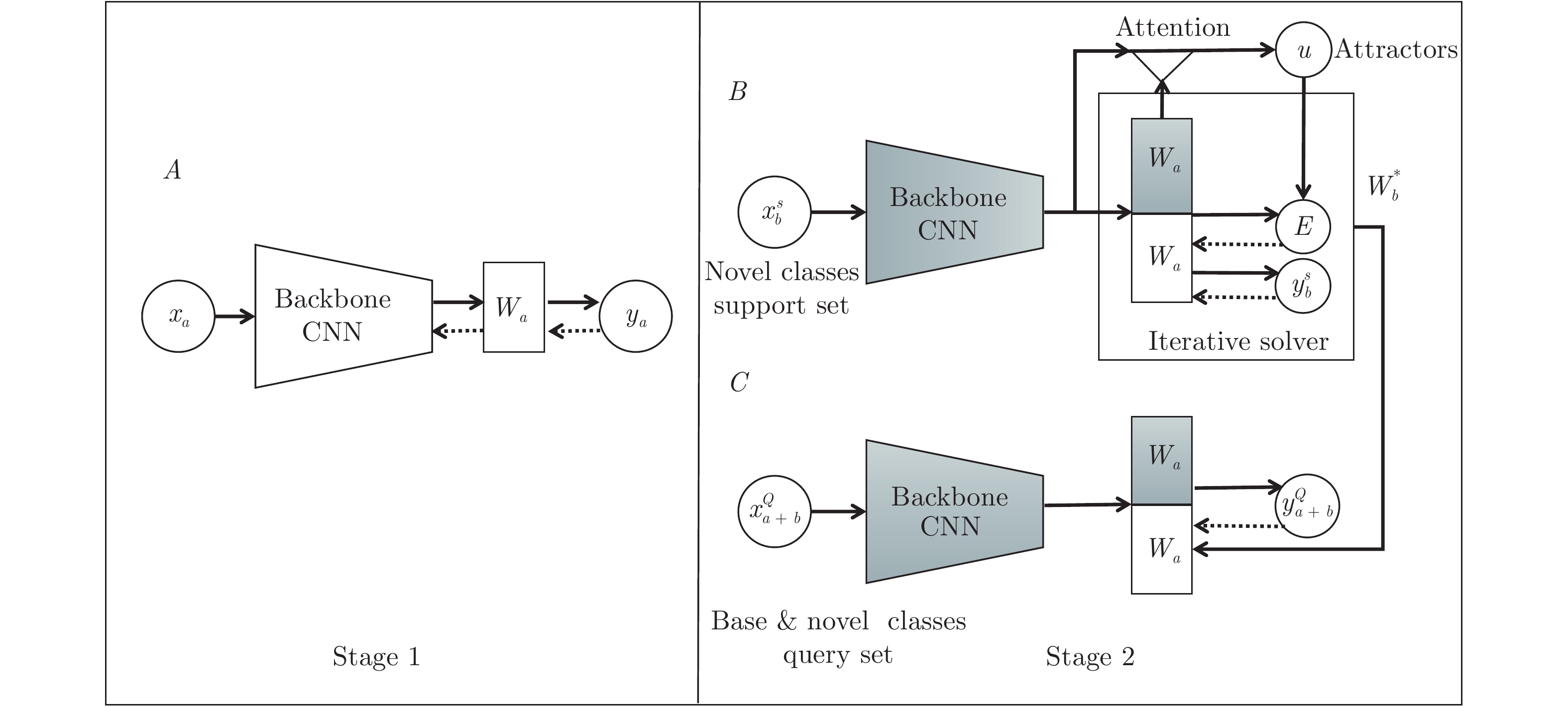
In 2019, a research combined incremental learning with meta learning, and proposed the Attention attractor networks (AAN), which not only performs well in the new class, but also will not forget the knowledge learned in the base class. As shown in Fig. 5, for a given new task, it will learn a parameter, which represents the contribution of the task in the classification, so that the classifier is more flexible and applicable, and it is easier to classify a new sample.
Optimization based meta learning
For the small sample dataset tuning strategy, the model is pretrained on the large dataset, and then do a simple tuning on the small dataset. However, the pretrained model can not guarantee a good initialization parameter for tuning. The optimization based meta learning can ensure the network learning to a good initialization, making the model easier to tune for new tasks.
Finn et al. [33] proposed a Model-agnostic meta-learning (MAML) algorithm in 2017. The proposed model agnostic meta-learning algorithm uses a few gradient iteration steps to learn parameters suitable for new tasks, and can match any model trained by gradient descent method. Each different task will produce different loss. The loss of the model on the task is used to optimize the parameters, so that it can be quickly applied to the new classification task. However, MAML is very sensitive to the structure of neural network, which makes the training process unstable. Reptile, a meta learning model based on optimization proposed by Nichol et al. [34] also initializes the parameters of learning network. Different from MAML, Reptile does not require differentiation in parameter optimization.
Ethical oriented implications
Interpretability
In the field of signal processing, models receive signals, then obtain information from them, and finally refine the information into knowledge. This is a matter of different levels and connotations. However, for visual tasks, it is often to find some significant local areas in the image, and then collect some features and targets in the area. Therefore, from this point of view, interpretative learning is helpful to the development of Few-shot learning, but how to promote and combine knowledge is still a challenging or open problem.
In the future, the interpretability of the model will certainly promote the development of Few-shot learning. The reason why Few-shot learning can be realized is that we can establish the association between classes, and transfer the semantic information of the so-called known class to the unknown class. How do categories relate? In fact, behind the category is the combination of some concepts, such as whether there are four legs, fur, what color and so on. So if we can learn the causal relationship between samples and categories from the existing classification models, and know the differences between categories, as well as the corresponding relationship between models and concepts, and try to solve the problem between zero samples and small samples, we can trace back to the root of transfer learning.
In addition, the interpretability of deep learning may focus more on the description of features. In fact, some of the initial work of Few-shot learning has always been done with the idea of interpretability, that is, mapping X to Y, where Y is the space of H. Then, we used this semantic interpretability to do Few-shot learning. If we only consider the interpretability of deep learning features, it is equivalent to how to better extract X and construct Few-shot learning from X.
Privacy
Since Few-shot learning always has a feature of collaborative, because models should learn knowledge based on the task specific information. There is inherent risk of privacy disclosure in Few-shot learning. Therefore, as far as parameter transfer algorithms are concerned, even though they can perform specific tasks to prevent direct access to private data, they are far from enough in terms of privacy protection. Researches [35] and [36] point out that only by accessing the model, the opponent may maliciously infer the details of training data. In addition, Carlini et al. [36] proved that the general sequence models can effectively store sensitive data (for example, the user’s private message text), and the attacker can still recover the user’s training data even after an epoch. Private data can be attacked in parameter transfer algorithms. That is a not acceptable threat to the data users. Currently, there are mainly two kinds of methods to protect the data privacy among tasks.
Differential privacy
Differential privacy is a common privacy protection method, which provides a strict and standard example, but does not disclose much privacy. Actually, whether the user’s records are included in the summary results or not, it provides a protection because attackers can only obtain similar data information. Differential privacy, a method based on privacy protection, has been widely studied in [37][38]. Dwork et al. [39], which is the original basis of other studies in differential privacy. Random noise can help keep statistical usefulness and protect data privacy. Although it will reduce the model performance in terms of accuracy, in the case of large amount of data, the impact of adding noise is acceptable. Chaudhuri et al. [40] proposed an objective perturbed privacy preserving method to disturb the loss function before optimizing the classifier and control the trade-off between performance and privacy. Papernot et al. [41] proposed PATE (Private Aggregation of Teacher Ensembles), which is a universal learning strategy using knowledge aggregation. It transfers all the knowledge from a teacher model to a student model. This ensures data privacy with a noisy teacher answer aggregation. Besides, Phan et al. [42] proposed a private convolutional deep belief network. In this model, the adaptive Laplacian mechanism is used to destroy the energy based loss function of traditional CDBNs.
Homomorphic encryption
Homomorphic encryption is widely used in the storage and calculation of private data [43][44][45][46], so that users can obtain the a good result after retrieving and comparing on the encrypted data. Actually, this process is without data decryption. Homomorphic encryption directly uses specific algebraic operations on ciphertext, and these operations generate encryption results that match the results of the same operations on plaintext. Since it is operated directly on the ciphertext, if there is no secret key for decryption, no information will be revealed. The Paillier algorithm is another homomorphic encryption method which has addition operation on a ciphertext. The model will generate public key and private key, which have the same size to define the encryption range of plaintext.
Conclusion
This blog classifies and summarizes the current image classification algorithms based on Few-shot learning. According to the modeling methods of different data types, Few-shot image classification algorithms are divided into convolution neural network model and graph neural network model. Convolution neural network model is divided into four learning paradigms: transfer learning, meta learning, Bayesian learning and dual learning. Two kinds of algorithms are introduced in detail. Finally, for the current Few-shot image classification algorithm, we discuss the ethical oriented implications in terms of interpretability and privacy.
References
- Lowe, D. G. Distinctive image features from scale-invariant keypoints. International journal of computer vision 60, 91–110 (2004).
- Dalal, N. & Triggs, B. Histograms of oriented gradients for human detection in 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05) 1 (2005), 886–893.
- Csurka, G., Dance, C., Fan, L., Willamowski, J. & Bray, C. Visual categorization with bags of keypoints in Workshop on statistical learning in computer vision, ECCV 1 (2004), 1–2.
- Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25, 1097–1105 (2012).
- Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K. & Wierstra, D. Matching networks for one shot learning. arXiv preprint arXiv:1606.04080 (2016).
- Lake, B., Salakhutdinov, R., Gross, J. & Tenenbaum, J. One shot learning of simple visual concepts in Proceedings of the annual meeting of the cognitive science society 33 (2011).
- Qi, G.-J. & Luo, J. Small data challenges in big data era: A survey of recent progress on unsupervised and semi-supervised methods. IEEE Transactions on Pattern Analysis and Machine Intelligence (2020).
- Wang, Y., Yao, Q., Kwok, J. T. & Ni, L. M. Generalizing from a few examples: A survey on few-shot learning. ACM Computing Surveys (CSUR) 53, 1–34 (2020).
- Mensink, T., Verbeek, J., Perronnin, F. & Csurka, G. Metric learning for large scale image classification: Generalizing to new classes at near-zero cost in European Conference on Computer Vision (2012), 488–501.
- Rohrbach, M., Ebert, S. & Schiele, B. Transfer learning in a transductive setting. Advances in neural information processing systems 26, 46–54 (2013).
- Lampert, C. H., Nickisch, H. & Harmeling, S. Attribute-based classification for zero-shot visual object categorization. IEEE transactions on pattern analysis and machine intelligence 36, 453–465 (2013).
- Fu, Y., Hospedales, T. M., Xiang, T. & Gong, S. Transductive multi-view zero-shot learning. IEEE transactions on pattern analysis and machine intelligence 37, 2332–2345 (2015).
- Wah, C., Branson, S., Welinder, P., Perona, P. & Belongie, S. The caltech-ucsd birds-200- 2011 dataset (2011).
- Fu, Y., Hospedales, T. M., Xiang, T. & Gong, S. Learning multimodal latent attributes. IEEE transactions on pattern analysis and machine intelligence 36, 303–316 (2013).
- Jia, Y. & Darrell, T. Latent task adaptation with large-scale hierarchies in Proceedings of the IEEE International Conference on Computer Vision (2013), 2080–2087.
- Dixit, M., Kwitt, R., Niethammer, M. & Vasconcelos, N. Aga: Attribute-guided augmentation in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017), 7455–7463.
- Bartunov, S. & Vetrov, D. Few-shot generative modelling with generative matching networks in International Conference on Artificial Intelligence and Statistics (2018), 670–678.
- Wang, P. et al. Multi-attention network for one shot learning in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017), 2721–2729.
- Koch, G., Zemel, R. & Salakhutdinov, R. Siamese neural networks for one-shot image recognition in ICML deep learning workshop 2 (2015).
- Goldberger, J., Hinton, G. E., Roweis, S. & Salakhutdinov, R. R. Neighbourhood components analysis. Advances in neural information processing systems 17, 513–520 (2004).
- Salakhutdinov, R. & Hinton, G. Learning a nonlinear embedding by preserving class neighbourhood structure in Artificial Intelligence and Statistics (2007), 412–419.
- Gidaris, S. & Komodakis, N. Dynamic few-shot visual learning without forgetting in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), 4367–4375.
- Et al. 47, 297–315 (2021).
- Qiao, S., Liu, C., Shen, W. & Yuille, A. L. Few-shot image recognition by predicting parameters from activations in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), 7229–7238.
- Aytar, Y. & Zisserman, A. Tabula rasa: Model transfer for object category detection in 2011 international conference on computer vision (2011), 2252–2259.
- Tommasi, T., Orabona, F. & Caputo, B. Safety in numbers: Learning categories from few examples with multi model knowledge transfer in 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (2010), 3081–3088.
- Pan, S. J. & Yang, Q. A survey on transfer learning. IEEE Transactions on knowledge and data engineering 22, 1345–1359 (2009).
- Hariharan, B. & Girshick, R. Low-shot visual recognition by shrinking and hallucinating features in Proceedings of the IEEE International Conference on Computer Vision (2017), 3018–3027.
- Choi, J., Krishnamurthy, J., Kembhavi, A. & Farhadi, A. Structured set matching networks for one-shot part labeling in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018), 3627–3636.
- Hinton, G., Vinyals, O. & Dean, J. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015).
- Oquab, M., Bottou, L., Laptev, I. & Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks in Proceedings of the IEEE conference on computer vision and pattern recognition (2014), 1717–1724.
- Qi, H., Brown, M. & Lowe, D. G. Low-shot learning with imprinted weights in Proceedings of the IEEE conference on computer vision and pattern recognition (2018), 5822–5830.
- Sung, F. et al. Learning to compare: Relation network for few-shot learning in Proceedings of the IEEE conference on computer vision and pattern recognition (2018), 1199–1208.
- Finn, C., Abbeel, P. & Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks in International Conference on Machine Learning (2017), 1126–1135.
- Nichol, A., Achiam, J. & Schulman, J. On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999 (2018).
- Shokri, R., Theodorakopoulos, G., Le Boudec, J.-Y. & Hubaux, J.-P. Quantifying location privacy. In proceedings of IEEE Symposium on Security and Privacy (sp) 2011.
- Carlini, N., Liu, C., Kos, J., Erlingsson, Ú. & Song, D. The secret sharer: Measuring unintended neural network memorization & extracting secrets (2018).
- Gong, M., Xie, Y., Pan, K., Feng, K. & Qin, A. K. A survey on differentially private machine learning. IEEE Computational Intelligence Magazine 15, 49–64 (2020).
- Zhang, S., Liu, L., Chen, Z. & Zhong, H. Probabilistic matrix factorization with personalized differential privacy. Knowledge-Based Systems 183, 104864 (2019).
- Dwork, C. Differential privacy: A survey of results in International conference on theory and applications of models of computation (2008), 1–19.
- Chaudhuri, K., Monteleoni, C. & Sarwate, A. D. Differentially private empirical risk minimization. Journal of Machine Learning Research 12 (2011).
- Papernot, N., Abadi, M., Erlingsson, U., Goodfellow, I. & Talwar, K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv preprint arXiv:1610.05755 (2016).
- Phan, N., Wang, Y., Wu, X. & Dou, D. Differential privacy preservation for deep auto-encoders: an application of human behavior prediction in Proceedings of the AAAI Conference on Artificial Intelligence 30 (2016).
- Salem, M., Taheri, S. & Yuan, J.-S. Utilizing transfer learning and homomorphic encryption in a privacy preserving and secure biometric recognition system. Computers 8, 3 (2019).
- Kim, M., Song, Y., Wang, S., Xia, Y. & Jiang, X. Secure logistic regression based on homomorphic encryption: Design and evaluation. JMIR medical informatics 6, e19 (2018).
- Aono, Y., Hayashi, T., Wang, L., Moriai, S., et al. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Transactions on Information Forensics and Security 13, 1333–1345 (2017).
- Rahman, M. S., Khalil, I., Alabdulatif, A. & Yi, X. Privacy preserving service selection using fully homomorphic encryption scheme on untrusted cloud service platform. KnowledgeBased Systems 180, 104–115 (2019).